Outlier removal
Renee Matthews edits
2025-08-21
Last updated: 2025-08-25
Checks: 7 0
Knit directory: DXR_continue/
This reproducible R Markdown analysis was created with workflowr (version 1.7.1). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20250701) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 5383e33. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: data/Cormotif_data/
Ignored: data/DER_data/
Ignored: data/alignment_summary.txt
Ignored: data/all_peak_final_dataframe.txt
Ignored: data/cell_line_info_.tsv
Ignored: data/full_summary_QC_metrics.txt
Ignored: data/motif_lists/
Ignored: data/number_frag_peaks_summary.txt
Untracked files:
Untracked: analysis/Motif_cluster_analysis.Rmd
Untracked: code/corMotifcustom.R
Untracked: code/making_analysis_file_summary.R
Unstaged changes:
Modified: analysis/Cormotif_analysis.Rmd
Modified: analysis/Cormotif_outlier_removal.Rmd
Modified: analysis/multiQC_cut_tag.Rmd
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown (analysis/Outlier_removal.Rmd) and
HTML (docs/Outlier_removal.html) files. If you’ve
configured a remote Git repository (see ?wflow_git_remote),
click on the hyperlinks in the table below to view the files as they
were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 5383e33 | reneeisnowhere | 2025-08-25 | adding PC percentages on plots |
| html | cafdfac | reneeisnowhere | 2025-08-22 | Build site. |
| Rmd | b8ad1c2 | reneeisnowhere | 2025-08-22 | outlier updates to code |
| html | ac6eb8d | reneeisnowhere | 2025-08-21 | Build site. |
| Rmd | 7e4a4f4 | reneeisnowhere | 2025-08-21 | wflow_publish(c("analysis/Outlier_removal.Rmd", "analysis/final_analysis.Rmd")) |
Final Anaylsis
Loading Packages
library(tidyverse)
library(readr)
library(edgeR)
library(ComplexHeatmap)
library(data.table)
library(dplyr)
library(stringr)
library(ggplot2)
library(viridis)
library(DT)
library(kableExtra)
library(genomation)
library(GenomicRanges)
library(chromVAR) ## For FRiP analysis and differential analysis
library(DESeq2) ## For differential analysis section
library(ggpubr) ## For customizing figures
library(corrplot) ## For correlation plot
library(ggpmisc)
library(gcplyr)
library(Rsubread)
library(limma)
library(ggrastr)
library(cowplot)
library(smplot2)
library(ggVennDiagram)Data Initialization
sampleinfo <- read_delim("data/sample_info.tsv", delim = "\t")Functions
drug_pal <- c("#8B006D","#DF707E","#F1B72B", "#3386DD","#707031","#41B333")
pca_plot <- function(pca_obj, df,
col_var = NULL,
shape_var = NULL,
text_var = NULL,
title = "") {
# variance explained
a <- prop_var_percent(pca_obj)
ggplot(df, aes_string(x = "PC1", y = "PC2")) +
geom_point(aes_string(color = col_var, shape = shape_var), size = 5) +
ggrepel::geom_text_repel(aes_string(label = text_var),
vjust = -.5,
max.overlaps = 30) +
labs(
title = title,
x = paste0("PC1 (", round(a[1], 1), "%)"),
y = paste0("PC2 (", round(a[2], 1), "%)")
) +
scale_color_manual(values = c(
"#8B006D", "#DF707E", "#F1B72B",
"#3386DD", "#707031", "#41B333"
))
}
pca_var_plot <- function(pca) {
# x: class == prcomp
pca.var <- pca$sdev ^ 2
pca.prop <- pca.var / sum(pca.var)
var.plot <-
qplot(PC, prop, data = data.frame(PC = 1:length(pca.prop),
prop = pca.prop)) +
labs(title = 'Variance contributed by each PC',
x = 'PC', y = 'Proportion of variance')
plot(var.plot)
}
calc_pca <- function(x) {
# Performs principal components analysis with prcomp
# x: a sample-by-gene numeric matrix
prcomp(x, scale. = TRUE, retx = TRUE)
}
get_regr_pval <- function(mod) {
# Returns the p-value for the Fstatistic of a linear model
# mod: class lm
stopifnot(class(mod) == "lm")
fstat <- summary(mod)$fstatistic
pval <- 1 - pf(fstat[1], fstat[2], fstat[3])
return(pval)
}
prop_var_percent <- function(pca_result){
# Ensure the input is a PCA result object
if (!inherits(pca_result, "prcomp")) {
stop("Input must be a result from prcomp()")
}
# Get the standard deviations from the PCA result
sdev <- pca_result$sdev
# Calculate the proportion of variance
proportion_variance <- (sdev^2) / sum(sdev^2)*100
return(proportion_variance)
}
plot_versus_pc <- function(df, pc_num, fac) {
# df: data.frame
# pc_num: numeric, specific PC for plotting
# fac: column name of df for plotting against PC
pc_char <- paste0("PC", pc_num)
# Calculate F-statistic p-value for linear model
pval <- get_regr_pval(lm(df[, pc_char] ~ df[, fac]))
if (is.numeric(df[, f])) {
ggplot(df, aes_string(x = f, y = pc_char)) + geom_point() +
geom_smooth(method = "lm") + labs(title = sprintf("p-val: %.2f", pval))
} else {
ggplot(df, aes_string(x = f, y = pc_char)) + geom_boxplot() +
labs(title = sprintf("p-val: %.2f", pval))
}
}
x_axis_labels = function(labels, every_nth = 1, ...) {
axis(side = 1,
at = seq_along(labels),
labels = F)
text(
x = (seq_along(labels))[seq_len(every_nth) == 1],
y = par("usr")[3] - 0.075 * (par("usr")[4] - par("usr")[3]),
labels = labels[seq_len(every_nth) == 1],
xpd = TRUE,
...
)
}
volcanosig <- function(df, psig.lvl) {
df <- df %>%
mutate(threshold = ifelse(adj.P.Val > psig.lvl, "A", ifelse(adj.P.Val <= psig.lvl & logFC<=0,"B","C")))
# ifelse(adj.P.Val <= psig.lvl & logFC >= 0,"B", "C")))
##This is where I could add labels, but I have taken out
# df <- df %>% mutate(genelabels = "")
# df$genelabels[1:topg] <- df$rownames[1:topg]
ggplot(df, aes(x=logFC, y=-log10(P.Value))) +
ggrastr::geom_point_rast(aes(color=threshold))+
# geom_text_repel(aes(label = genelabels), segment.curvature = -1e-20,force = 1,size=2.5,
# arrow = arrow(length = unit(0.015, "npc")), max.overlaps = Inf) +
#geom_hline(yintercept = -log10(psig.lvl))+
xlab(expression("Log"[2]*" FC"))+
ylab(expression("-log"[10]*"P Value"))+
scale_color_manual(values = c("black", "red","blue"))+
theme_cowplot()+
ylim(0,25)+
xlim(-6,6)+
theme(legend.position = "none",
plot.title = element_text(size = rel(1.5), hjust = 0.5),
axis.title = element_text(size = rel(0.8)))
}Feature Counts
H3K27ac_merged <- read_delim("data/peaks/H3K27ac_FINAL_counts.txt",
delim = "\t", escape_double = FALSE,
trim_ws = TRUE, skip = 1)
H3K27me3_merged <- read_delim("data/peaks/H3K27me3_FINAL_counts.txt",
delim = "\t", escape_double = FALSE,
trim_ws = TRUE, skip = 1)
H3K36me3_merged <- read_delim("data/peaks/H3K36me3_FINAL_counts.txt",
delim = "\t", escape_double = FALSE,
trim_ws = TRUE, skip = 1)
H3K9me3_merged <- read_delim("data/peaks/H3K9me3_FINAL_counts.txt",
delim = "\t", escape_double = FALSE,
trim_ws = TRUE, skip = 1)
rename_list <- sampleinfo %>%
mutate(stem= "_nobl.bam") %>%
mutate(prefix=paste0("/scratch/10819/styu/MW_multiQC/peaks/",Histone_Mark,"/",Treatment,"/",Timepoint,"/")) %>%
mutate(oldname=paste0(prefix,`Library ID`,"/",`Library ID`,stem)) %>%
mutate(newname=paste0(Individual,"_",Treatment,"_",Timepoint)) %>%
dplyr::select(oldname,newname)
rename_vec <- setNames(rename_list$newname, rename_list$oldname)
names(H3K27ac_merged)[names(H3K27ac_merged) %in% names(rename_vec)] <- rename_vec[names(H3K27ac_merged)[names(H3K27ac_merged) %in% names(rename_vec)]]
names(H3K27me3_merged)[names(H3K27me3_merged) %in% names(rename_vec)] <- rename_vec[names(H3K27me3_merged)[names(H3K27me3_merged) %in% names(rename_vec)]]
names(H3K36me3_merged)[names(H3K36me3_merged) %in% names(rename_vec)] <- rename_vec[names(H3K36me3_merged)[names(H3K36me3_merged) %in% names(rename_vec)]]
names(H3K9me3_merged)[names(H3K9me3_merged) %in% names(rename_vec)] <- rename_vec[names(H3K9me3_merged)[names(H3K9me3_merged) %in% names(rename_vec)]]Removing outliers and reanalyzing
This is removing outliers in H3K36me3: Ind1_VEH_144R and in H3K9me3: Ind1_VEH_24T, Ind3_DOX_24T, Ind5_DOX_144R
H3K36me3_merged <- H3K36me3_merged %>%
dplyr::select(!Ind1_VEH_144R)
H3K9me3_merged<- H3K9me3_merged %>%
dplyr::select(!Ind1_VEH_24T) %>%
dplyr::select(!Ind3_DOX_24T) %>%
dplyr::select(!Ind5_DOX_144R)H3K27ac Count Analysis
H3K27ac_merged_raw <- H3K27ac_merged %>%
dplyr::select(Geneid,contains("Ind")) %>%
column_to_rownames("Geneid") %>%
as.matrix()
H3K27ac_merged_lcpm <- H3K27ac_merged %>%
dplyr::select(Geneid,contains("Ind")) %>%
column_to_rownames("Geneid") %>%
cpm(., log = TRUE)
H3K27ac_merged_cor <- H3K27ac_merged_lcpm %>%
cor()
annomat <- data.frame(sample=colnames(H3K27ac_merged_cor)) %>%
separate_wider_delim(sample,delim="_",names=c("Ind","Treatment","Timepoint"),cols_remove = FALSE) %>%
mutate(Treatment=factor(Treatment, levels = c("VEH","5FU","DOX")),
Timepoint=factor(Timepoint, levels =c("24T","24R","144R"))) %>%
column_to_rownames("sample")
heatmap_first <- ComplexHeatmap::HeatmapAnnotation(df = annomat)
Heatmap(H3K27ac_merged_cor,
top_annotation = heatmap_first,
column_title="Unfiltered log2cpm H3K27ac, no removal")H3K27me3 Count Analysis
H3K27me3_merged_raw <- H3K27me3_merged %>%
dplyr::select(Geneid,contains("Ind")) %>%
column_to_rownames("Geneid") %>%
as.matrix()
H3K27me3_merged_lcpm <- H3K27me3_merged %>%
dplyr::select(Geneid,contains("Ind")) %>%
column_to_rownames("Geneid") %>%
cpm(., log = TRUE)
H3K27me3_merged_cor <- H3K27me3_merged_lcpm %>%
cor()
annomat <- data.frame(sample=colnames(H3K27me3_merged_cor)) %>%
separate_wider_delim(sample,delim="_",names=c("Ind","Treatment","Timepoint"),cols_remove = FALSE) %>%
mutate(Treatment=factor(Treatment, levels = c("VEH","5FU","DOX")),
Timepoint=factor(Timepoint, levels =c("24T","24R","144R"))) %>%
column_to_rownames("sample")
heatmap_first <- ComplexHeatmap::HeatmapAnnotation(df = annomat)
Heatmap(H3K27me3_merged_cor,
top_annotation = heatmap_first,
column_title="Unfiltered log2cpm H3K27me3 with no removal")H3K36me3 Count Analysis
H3K36me3_merged_raw <- H3K36me3_merged %>%
dplyr::select(Geneid,contains("Ind")) %>%
column_to_rownames("Geneid") %>%
as.matrix()
H3K36me3_merged_lcpm <- H3K36me3_merged %>%
dplyr::select(Geneid,contains("Ind")) %>%
column_to_rownames("Geneid") %>%
cpm(., log = TRUE)
H3K36me3_merged_cor <- H3K36me3_merged_lcpm %>%
cor()
annomat <- data.frame(sample=colnames(H3K36me3_merged_cor)) %>%
separate_wider_delim(sample,delim="_",names=c("Ind","Treatment","Timepoint"),cols_remove = FALSE) %>%
mutate(Treatment=factor(Treatment, levels = c("VEH","5FU","DOX")),
Timepoint=factor(Timepoint, levels =c("24T","24R","144R"))) %>%
column_to_rownames("sample")
heatmap_first <- ComplexHeatmap::HeatmapAnnotation(df = annomat)
Heatmap(H3K36me3_merged_cor,
top_annotation = heatmap_first,
column_title="Unfiltered log2cpm H3K36me3 with removal of 1 sample")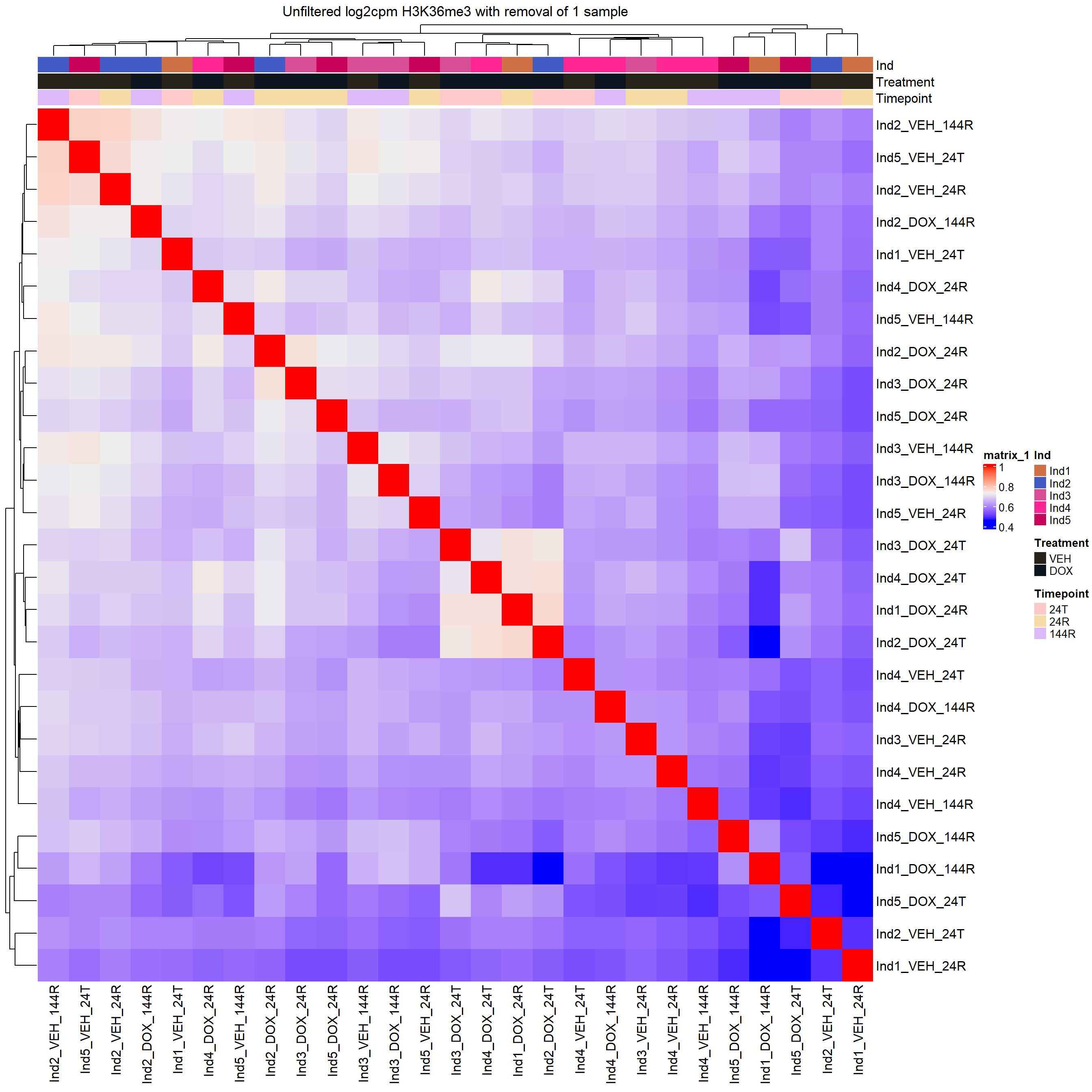
H3K9me3 Count Analysis
H3K9me3_merged_raw <- H3K9me3_merged %>%
dplyr::select(Geneid,contains("Ind")) %>%
column_to_rownames("Geneid") %>%
as.matrix()
H3K9me3_merged_lcpm <- H3K9me3_merged %>%
dplyr::select(Geneid,contains("Ind")) %>%
column_to_rownames("Geneid") %>%
cpm(., log = TRUE)
H3K9me3_merged_cor <- H3K9me3_merged_lcpm %>%
cor()
annomat <- data.frame(sample=colnames(H3K9me3_merged_cor)) %>%
separate_wider_delim(sample,delim="_",names=c("Ind","Treatment","Timepoint"),cols_remove = FALSE) %>%
mutate(Treatment=factor(Treatment, levels = c("VEH","5FU","DOX")),
Timepoint=factor(Timepoint, levels =c("24T","24R","144R"))) %>%
column_to_rownames("sample")
heatmap_first <- ComplexHeatmap::HeatmapAnnotation(df = annomat)
Heatmap(H3K9me3_merged_cor,
top_annotation = heatmap_first,
column_title="Unfiltered log2cpm H3K9me3 with Outlier removal")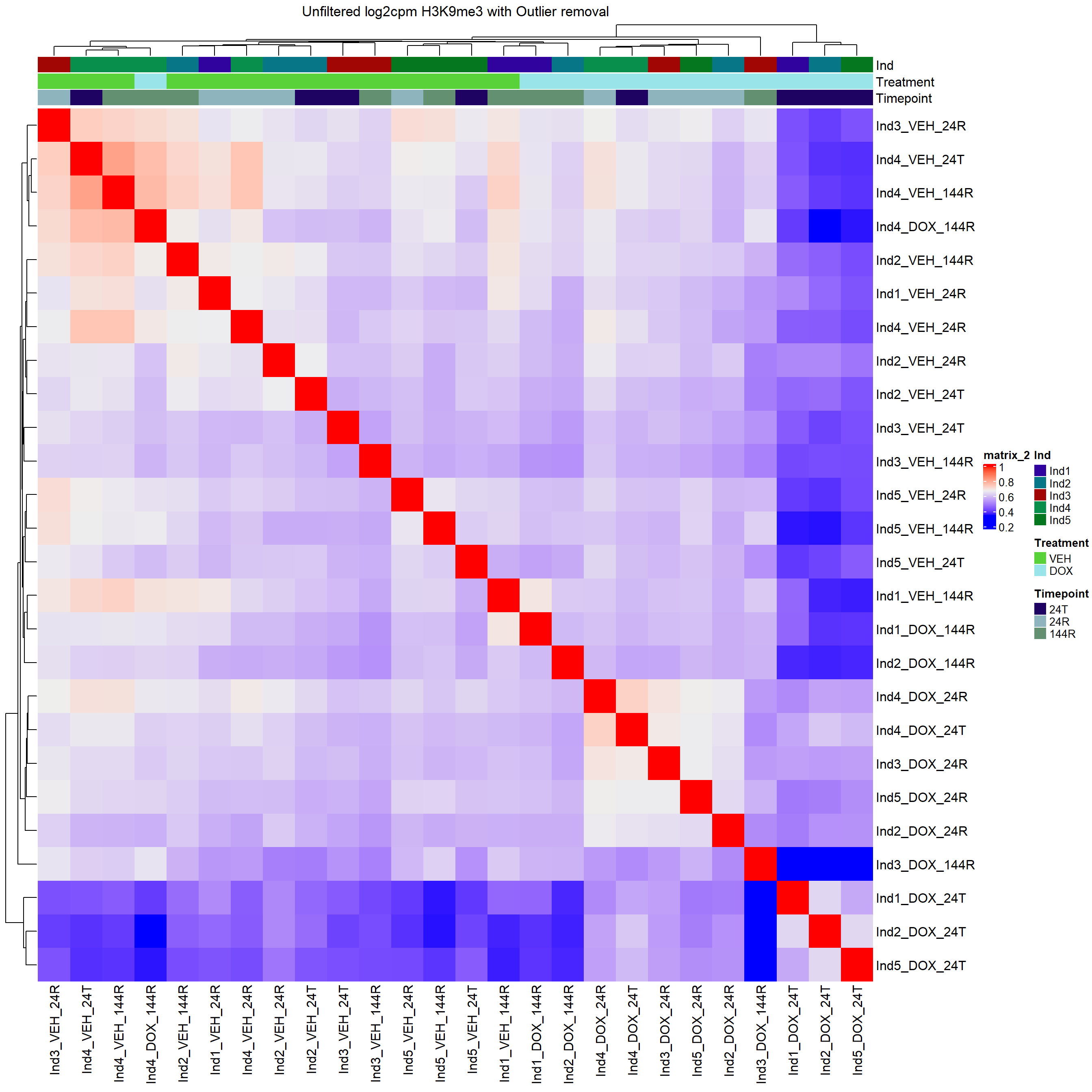
Differential Analysis
Filtering Sex Chromosomes
Removing chrX and chrY
# H3K27ac_merged_raw <- H3K27ac_merged_raw[rowMeans(H3K27ac_merged_lcpm)>0,]
# H3K27ac_merged_raw <- H3K27ac_merged_raw[!grepl("chrY",rownames(H3K27ac_merged_raw)),]
# H3K27ac_merged_raw <- H3K27ac_merged_raw[!grepl("chrX",rownames(H3K27ac_merged_raw)),]
# H3K27me3_merged_raw <- H3K27me3_merged_raw[rowMeans(H3K27me3_merged_lcpm)>0,]
# H3K27me3_merged_raw <- H3K27me3_merged_raw[!grepl("chrY",rownames(H3K27me3_merged_raw)),]
# H3K27me3_merged_raw <- H3K27me3_merged_raw[!grepl("chrX",rownames(H3K27me3_merged_raw)),]
H3K36me3_merged_raw <- H3K36me3_merged_raw[rowMeans(H3K36me3_merged_lcpm)>0,]
H3K36me3_merged_raw <- H3K36me3_merged_raw[!grepl("chrY",rownames(H3K36me3_merged_raw)),]
H3K36me3_merged_raw <- H3K36me3_merged_raw[!grepl("chrX",rownames(H3K36me3_merged_raw)),]
H3K9me3_merged_raw <- H3K9me3_merged_raw[rowMeans(H3K9me3_merged_lcpm)>0,]
H3K9me3_merged_raw <- H3K9me3_merged_raw[!grepl("chrY",rownames(H3K9me3_merged_raw)),]
H3K9me3_merged_raw <- H3K9me3_merged_raw[!grepl("chrX",rownames(H3K9me3_merged_raw)),]H3K36me3_merged_raw_lcpm <- H3K36me3_merged_raw %>%
cpm(., log = TRUE)
H3K36me3_merged_filt_cor <- H3K36me3_merged_raw_lcpm %>%
cor()
annomat <- data.frame(sample=colnames(H3K36me3_merged_filt_cor)) %>%
separate_wider_delim(sample,delim="_",names=c("Ind","Treatment","Timepoint"),cols_remove = FALSE) %>%
mutate(Treatment=factor(Treatment, levels = c("VEH","5FU","DOX")),
Timepoint=factor(Timepoint, levels =c("24T","24R","144R"))) %>%
column_to_rownames("sample")
heatmap_second <- ComplexHeatmap::HeatmapAnnotation(df = annomat)
Heatmap(H3K36me3_merged_filt_cor,
top_annotation = heatmap_second,
column_title="Filtered log2cpm H3K36me3 with removal of 1 sample")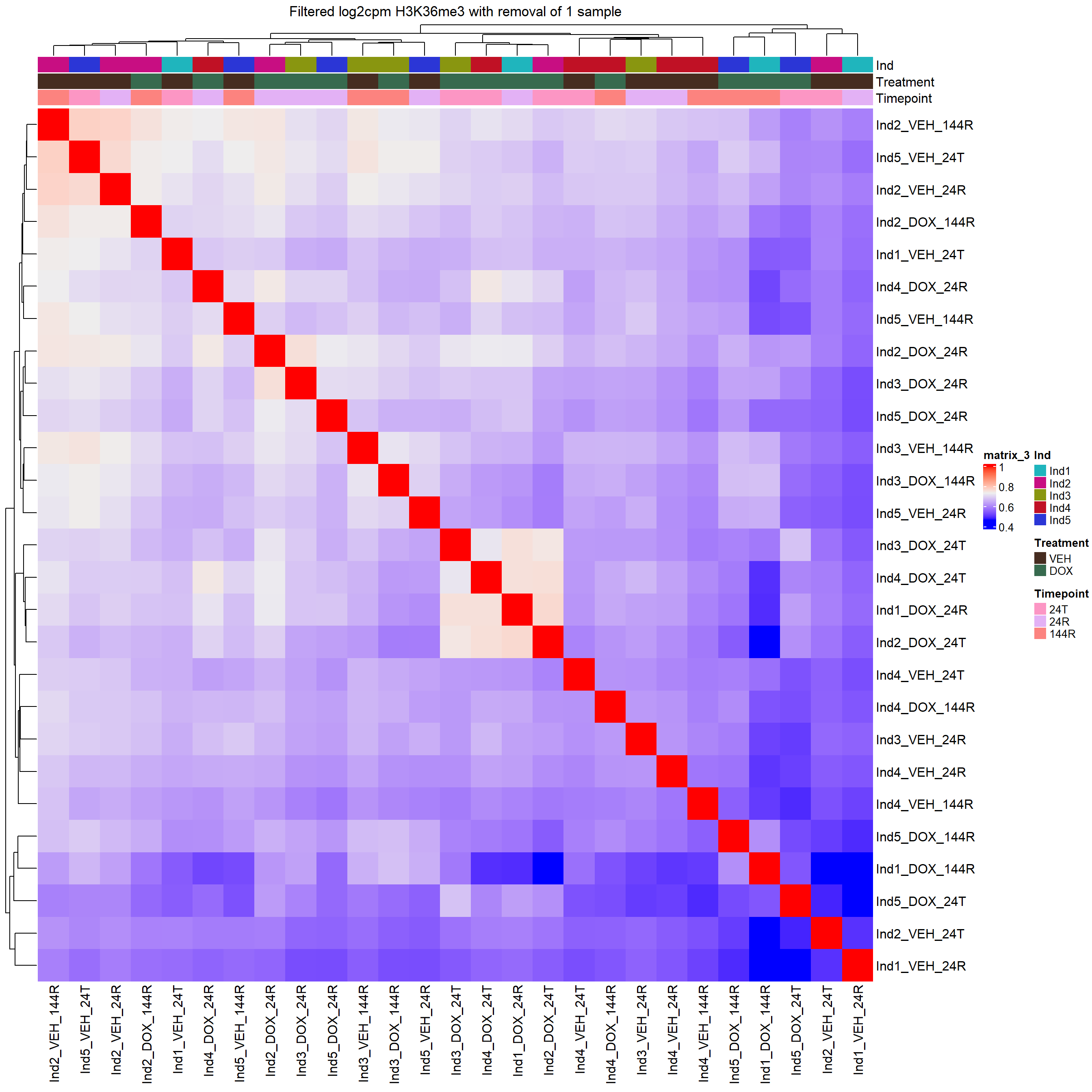
H3K9me3_merged_raw_lcpm <- H3K9me3_merged_raw %>%
cpm(., log = TRUE)
H3K9me3_merged_filt_cor <- H3K9me3_merged_raw_lcpm %>%
cor()
annomat <- data.frame(sample=colnames(H3K9me3_merged_filt_cor)) %>%
separate_wider_delim(sample,delim="_",names=c("Ind","Treatment","Timepoint"),cols_remove = FALSE) %>%
mutate(Treatment=factor(Treatment, levels = c("VEH","5FU","DOX")),
Timepoint=factor(Timepoint, levels =c("24T","24R","144R"))) %>%
column_to_rownames("sample")
heatmap_second <- ComplexHeatmap::HeatmapAnnotation(df = annomat)
Heatmap(H3K9me3_merged_filt_cor,
top_annotation = heatmap_second,
column_title="Filtered log2cpm H3K9me3 with removal of 3 samples")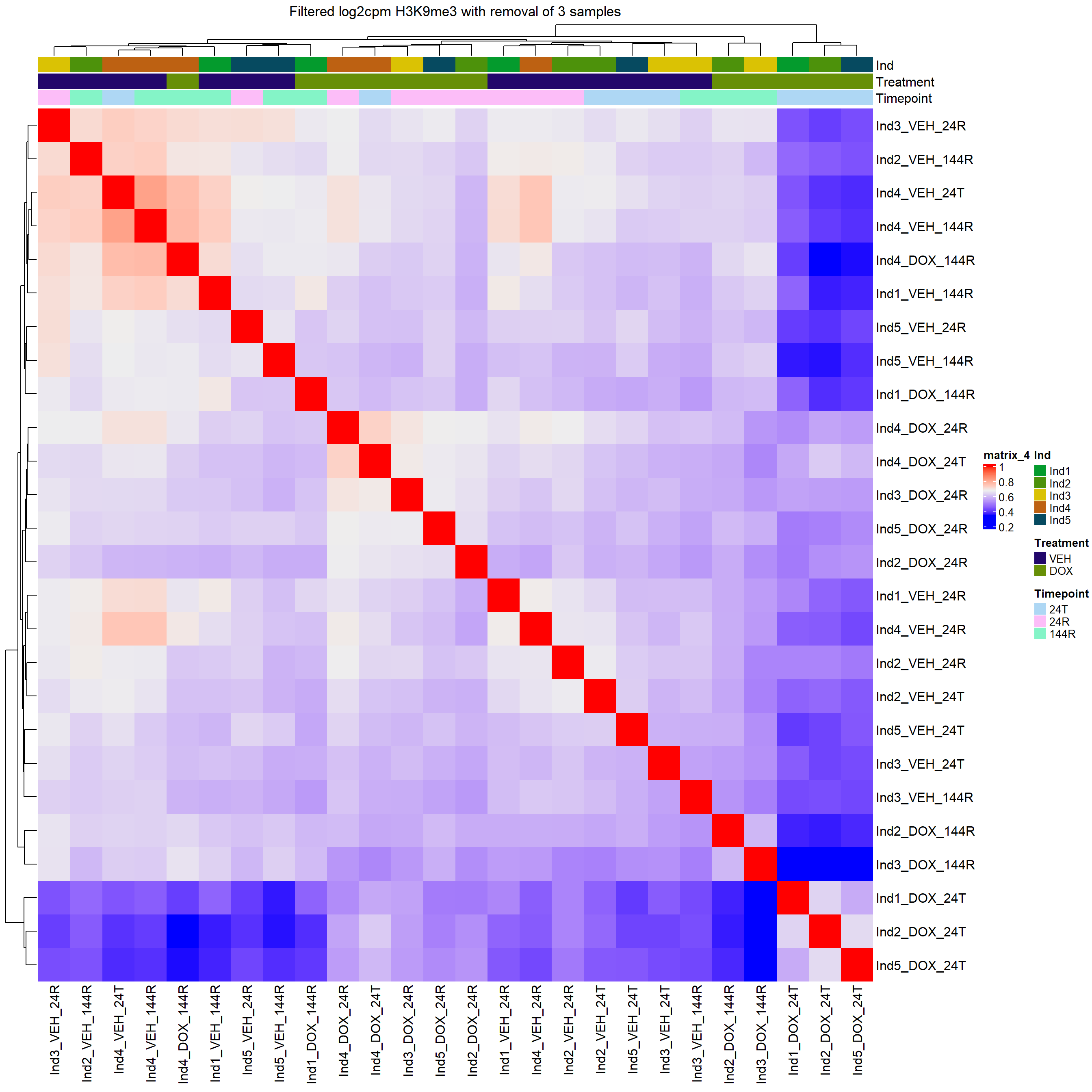
Setting up Matrix
# H3K27ac_annomat <- data.frame(timeset=colnames(H3K27ac_merged_raw)) %>%
# mutate(sample=timeset) %>%
# separate(timeset, into = c("ind","tx","time")) %>%
# mutate(tx=factor(tx, levels = c("VEH", "DOX")),
# time=factor(time, levels =c("24T","24R","144R"))) %>%
# mutate(ind = gsub("Ind", "", ind)) %>%
# mutate(txtime = paste0(tx, "_", time)) %>%
# mutate(group = txtime)
# H3K27ac_annomat$group <- H3K27ac_annomat$group %>%
# gsub("DOX_24T", "1", .) %>%
# gsub("DOX_24R", "2", .) %>%
# gsub("DOX_144R", "3", .) %>%
# gsub("VEH_24T", "4", .) %>%
# gsub("VEH_24R", "5", .) %>%
# gsub("VEH_144R", "6", .)
#
# H3K27me3_annomat <- data.frame(timeset=colnames(H3K27me3_merged_raw)) %>%
# mutate(sample=timeset) %>%
# separate(timeset, into = c("ind","tx","time")) %>%
# mutate(tx=factor(tx, levels = c("VEH", "DOX")),
# time=factor(time, levels =c("24T","24R","144R"))) %>%
# mutate(ind = gsub("Ind", "", ind)) %>%
# mutate(txtime = paste0(tx, "_", time)) %>%
# mutate(group = txtime)
# H3K27me3_annomat$group <- H3K27me3_annomat$group %>%
# gsub("DOX_24T", "1", .) %>%
# gsub("DOX_24R", "2", .) %>%
# gsub("DOX_144R", "3", .) %>%
# gsub("VEH_24T", "4", .) %>%
# gsub("VEH_24R", "5", .) %>%
# gsub("VEH_144R", "6", .)
H3K36me3_annomat <- data.frame(timeset=colnames(H3K36me3_merged_raw)) %>%
mutate(sample=timeset) %>%
separate(timeset, into = c("ind","tx","time")) %>%
mutate(tx=factor(tx, levels = c("VEH", "DOX")),
time=factor(time, levels =c("24T","24R","144R"))) %>%
mutate(ind = gsub("Ind", "", ind)) %>%
mutate(txtime = paste0(tx, "_", time)) %>%
mutate(group = txtime)
H3K36me3_annomat$group <- H3K36me3_annomat$group %>%
gsub("DOX_24T", "1", .) %>%
gsub("DOX_24R", "2", .) %>%
gsub("DOX_144R", "3", .) %>%
gsub("VEH_24T", "4", .) %>%
gsub("VEH_24R", "5", .) %>%
gsub("VEH_144R", "6", .)
H3K9me3_annomat <- data.frame(timeset=colnames(H3K9me3_merged_raw)) %>%
mutate(sample=timeset) %>%
separate(timeset, into = c("ind","tx","time")) %>%
mutate(tx=factor(tx, levels = c("VEH", "DOX")),
time=factor(time, levels =c("24T","24R","144R"))) %>%
mutate(ind = gsub("Ind", "", ind)) %>%
mutate(txtime = paste0(tx, "_", time)) %>%
mutate(group = txtime)
H3K9me3_annomat$group <- H3K9me3_annomat$group %>%
gsub("DOX_24T", "1", .) %>%
gsub("DOX_24R", "2", .) %>%
gsub("DOX_144R", "3", .) %>%
gsub("VEH_24T", "4", .) %>%
gsub("VEH_24R", "5", .) %>%
gsub("VEH_144R", "6", .)
# dge_H3K27ac <- edgeR::DGEList(counts = H3K27ac_merged_raw, group = H3K27ac_annomat$group, genes = row.names(H3K27ac_merged_raw))
# dge_H3K27me3 <- edgeR::DGEList(counts = H3K27me3_merged_raw, group = H3K27me3_annomat$group, genes = row.names(H3K27me3_merged_raw))
dge_H3K36me3 <- edgeR::DGEList(counts = H3K36me3_merged_raw, group = H3K36me3_annomat$group, genes = row.names(H3K36me3_merged_raw))
dge_H3K9me3 <- edgeR::DGEList(counts = H3K9me3_merged_raw, group = H3K9me3_annomat$group, genes = row.names(H3K9me3_merged_raw))
# dge_H3K27ac <- edgeR::calcNormFactors(dge_H3K27ac)
# dge_H3K27me3 <- edgeR::calcNormFactors(dge_H3K27me3)
dge_H3K36me3 <- edgeR::calcNormFactors(dge_H3K36me3)
dge_H3K9me3 <- edgeR::calcNormFactors(dge_H3K9me3)
# mm_H3K27ac <- model.matrix(~0 + H3K27ac_annomat$txtime)
# colnames(mm_H3K27ac) <- H3K27ac_annomat$txtime %>% unique()
# mm_H3K27me3 <- model.matrix(~0 + H3K27me3_annomat$txtime)
# colnames(mm_H3K27me3) <- H3K27me3_annomat$txtime %>% unique()
mm_H3K36me3 <- model.matrix(~0 + H3K36me3_annomat$txtime)
colnames(mm_H3K36me3) <- H3K36me3_annomat$txtime %>% unique()
mm_H3K9me3 <- model.matrix(~0 + H3K9me3_annomat$txtime)
colnames(mm_H3K9me3) <- H3K9me3_annomat$txtime %>% unique()PCA Plots
H3K27ac
# pca_H3K27ac <- calc_pca(t(H3K27ac_merged_lcpm))
# pca_var_plot(pca_H3K27ac)# pca_H3K27ac <- pca_H3K27ac$x %>% cbind(., H3K27ac_annomat)
# pca_plot(pca_H3K27ac, col_var = "time", shape_var = "tx", text_var = pca_H3K27ac$ind, title = "H3K27ac lcpm PCA")H3K27ac_merged_raw_lcpm <- H3K27ac_merged_raw %>%
cpm(., log = TRUE)
H3K27ac_merged_filt_cor <- H3K27ac_merged_raw_lcpm %>%
cor()
annomat <- data.frame(sample=colnames(H3K27ac_merged_filt_cor)) %>%
separate_wider_delim(sample,delim="_",names=c("Ind","Treatment","Timepoint"),cols_remove = FALSE) %>%
mutate(Treatment=factor(Treatment, levels = c("VEH","5FU","DOX")),
Timepoint=factor(Timepoint, levels =c("24T","24R","144R"))) %>%
column_to_rownames("sample")
heatmap_second <- ComplexHeatmap::HeatmapAnnotation(df = annomat)
Heatmap(H3K27ac_merged_filt_cor,
top_annotation = heatmap_second,
column_title="Filtered log2cpm H3K27ac with Standard Merging")H3K27me3
pca_H3K27me3 <- calc_pca(t(H3K27me3_merged_lcpm))
pca_var_plot(pca_H3K27me3)pca_H3K27me3 <- pca_H3K27me3$x %>% cbind(., H3K27me3_annomat)
pca_plot(pca_H3K27me3, col_var = "time", shape_var = "tx", text_var = pca_H3K27me3$ind, title = "H3K27me3 lcpm PCA")H3K36me3
pca_H3K36me3 <- calc_pca(t(H3K36me3_merged_lcpm))
pca_var_plot(pca_H3K36me3)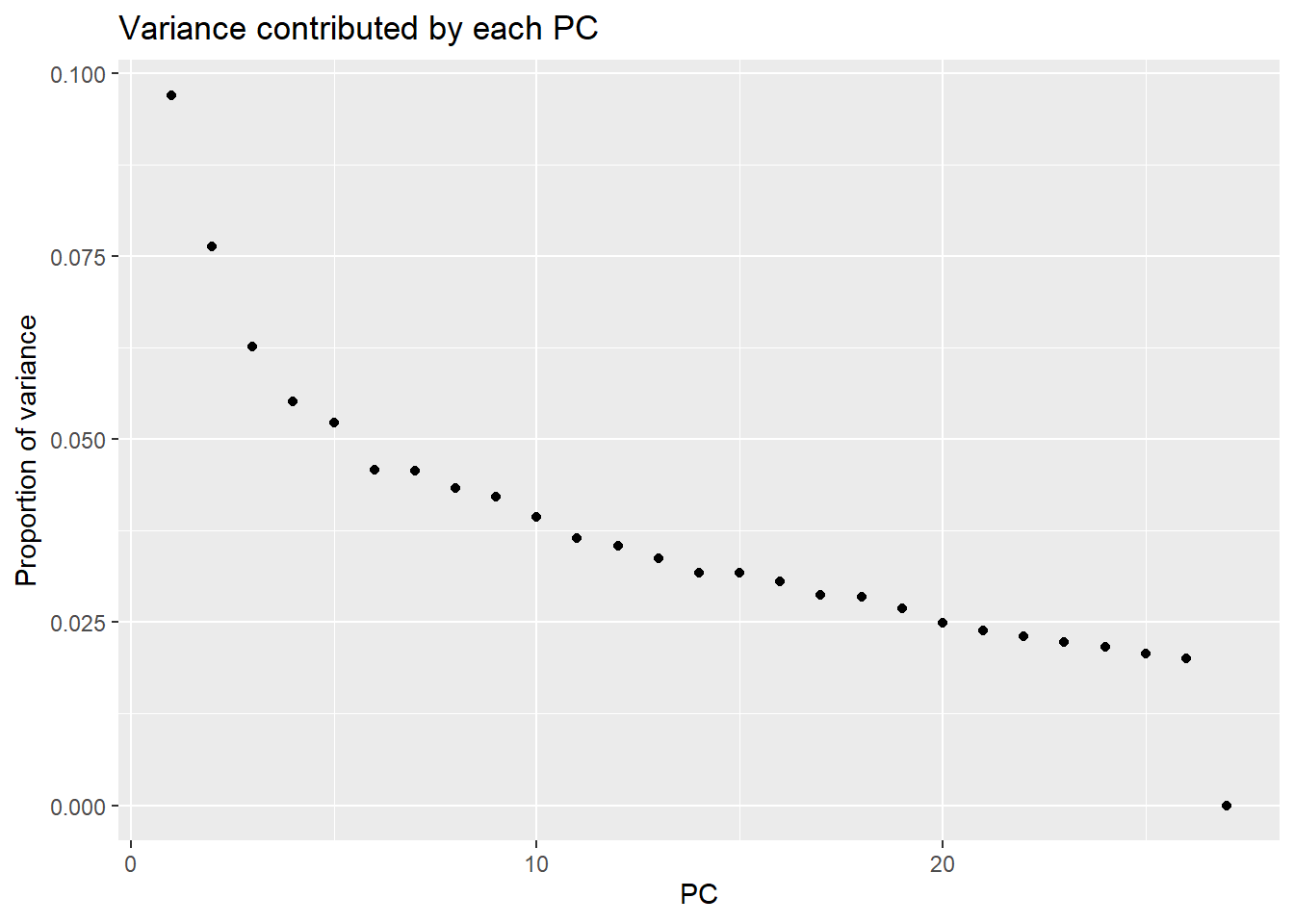
| Version | Author | Date |
|---|---|---|
| ac6eb8d | reneeisnowhere | 2025-08-21 |
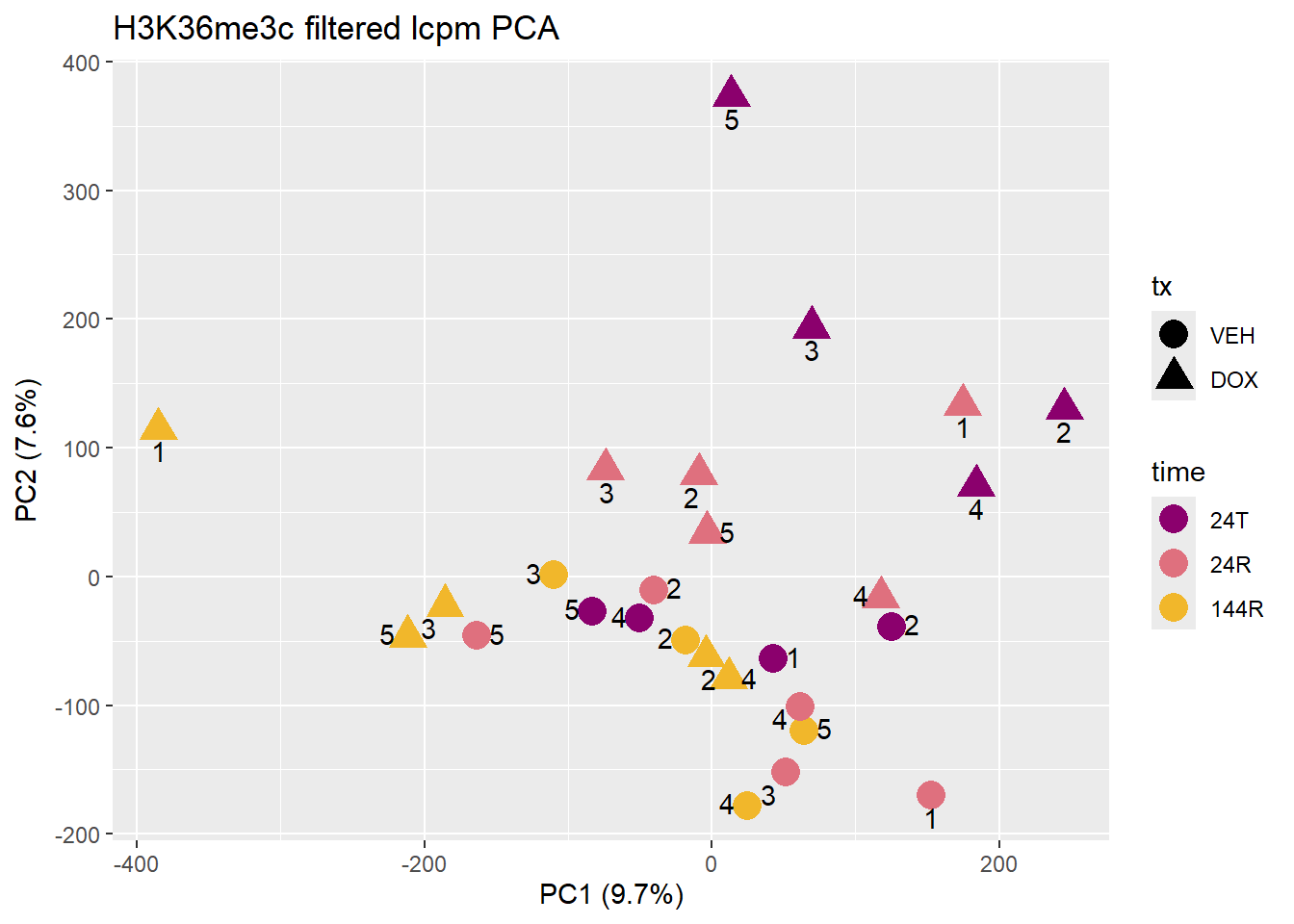
pca_H3K36me3_df <- data.frame(pca_H3K36me3$x , H3K36me3_annomat)
pca_plot(
pca_H3K36me3,
pca_H3K36me3_df,
col_var = "time",
shape_var = "tx",
text_var = "ind", # <-- string, not vector
title = "H3K36me3c filtered lcpm PCA"
) 
H3K9me3
pca_H3K9me3 <- calc_pca(t(H3K9me3_merged_lcpm))
pca_var_plot(pca_H3K9me3)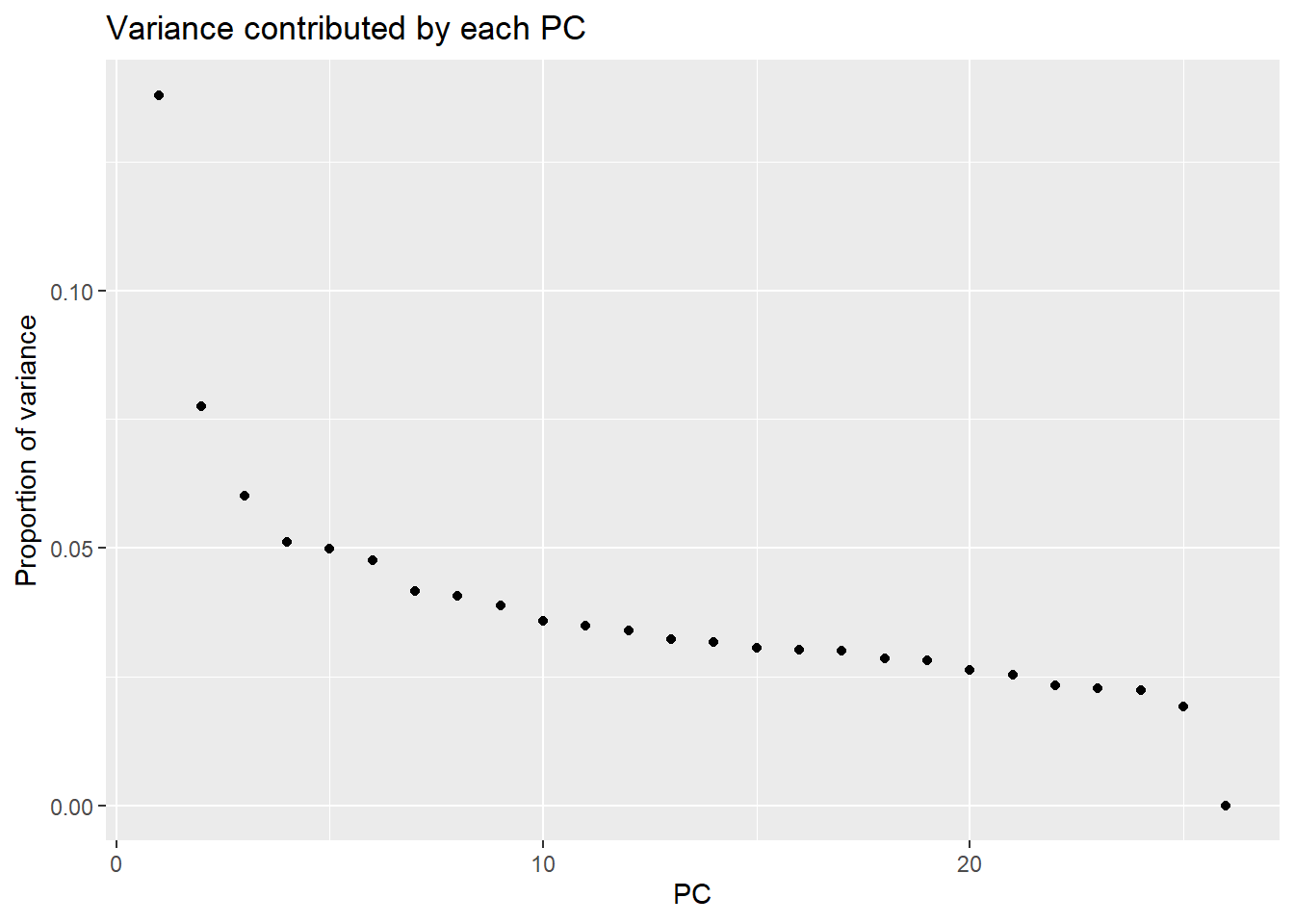
| Version | Author | Date |
|---|---|---|
| ac6eb8d | reneeisnowhere | 2025-08-21 |
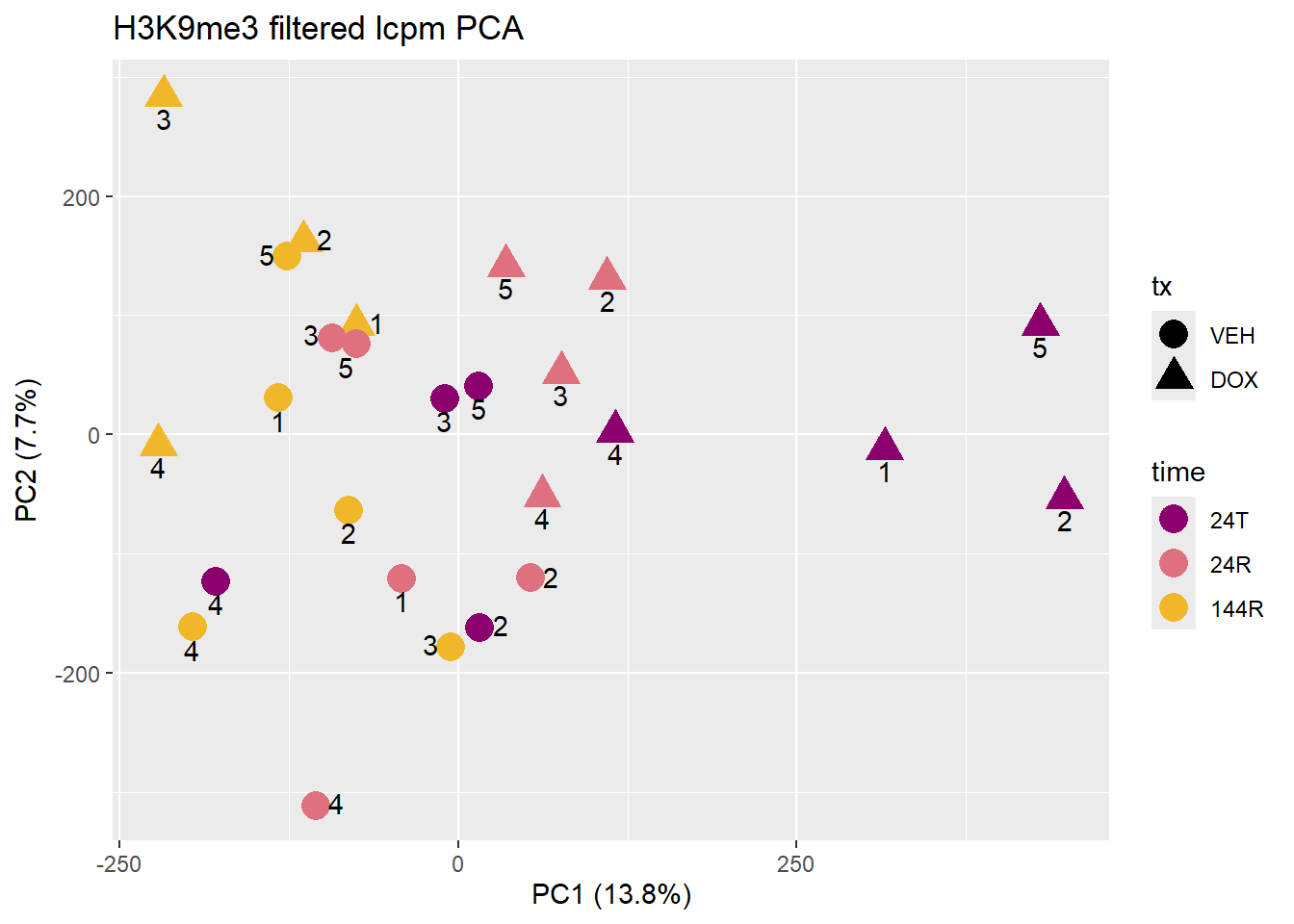
pca_H3K9me3_df <- data.frame(pca_H3K9me3$x , H3K9me3_annomat)
pca_plot(
pca_H3K9me3,
pca_H3K9me3_df,
col_var = "time",
shape_var = "tx",
text_var = "ind", # <-- string, not vector
title = "H3K9me3 filtered lcpm PCA"
) 
Differential Enrichment and Volcano Plots
H3K27ac
y <- voom(dge_H3K27ac, mm_H3K27ac, plot = FALSE)
corfit <- duplicateCorrelation(y, mm_H3K27ac, block = H3K27ac_annomat$ind)
v <- voom(dge_H3K27ac, mm_H3K27ac, block = H3K27ac_annomat$ind, correlation = corfit$consensus.correlation)
fit <- lmFit(v, mm_H3K27ac, block = H3K27ac_annomat$ind, correlation = corfit$consensus.correlation)
cm <- makeContrasts(
DOX_24T.VEH_24T = DOX_24T-VEH_24T,
DOX_24R.VEH_24R = DOX_24R-VEH_24R,
DOX_144R.VEH_144R = DOX_144R-VEH_144R,
levels = mm_H3K27ac)
fit2<- contrasts.fit(fit, contrasts=cm)
efit2 <- eBayes(fit2)
results = decideTests(efit2)
summary(results)plotSA(efit2, main="Mean-Variance trend for final model for H3K27ac")V.24T.top= topTable(efit2, coef=1, adjust.method="BH", number=Inf, sort.by="p")
V.24R.top= topTable(efit2, coef=2, adjust.method="BH", number=Inf, sort.by="p")
V.144R.top= topTable(efit2, coef=3, adjust.method="BH", number=Inf, sort.by="p")
H3K27ac_24T <- volcanosig(V.24T.top, 0.05)+ ggtitle("DOX 24T")
H3K27ac_24R <- volcanosig(V.24R.top, 0.05)+ ggtitle("DOX 24R")+ylab("")
H3K27ac_144R <- volcanosig(V.144R.top, 0.05)+ ggtitle("DOX 144R")+ylab("")
plot_grid(H3K27ac_24T, H3K27ac_24R, H3K27ac_144R, rel_widths =c(1,1,1))H3K27me3
y <- voom(dge_H3K27me3, mm_H3K27me3, plot = FALSE)
corfit <- duplicateCorrelation(y, mm_H3K27me3, block = H3K27me3_annomat$ind)
v <- voom(dge_H3K27me3, mm_H3K27me3, block = H3K27me3_annomat$ind, correlation = corfit$consensus.correlation)
fit <- lmFit(v, mm_H3K27me3, block = H3K27me3_annomat$ind, correlation = corfit$consensus.correlation)
cm <- makeContrasts(
DOX_24T.VEH_24T = DOX_24T-VEH_24T,
DOX_24R.VEH_24R = DOX_24R-VEH_24R,
DOX_144R.VEH_144R = DOX_144R-VEH_144R,
levels = mm_H3K27me3)
fit2<- contrasts.fit(fit, contrasts=cm)
efit2 <- eBayes(fit2)
results = decideTests(efit2)
summary(results)plotSA(efit2, main="Mean-Variance trend for final model for H3K27me3")V.24T.top= topTable(efit2, coef=1, adjust.method="BH", number=Inf, sort.by="p")
V.24R.top= topTable(efit2, coef=2, adjust.method="BH", number=Inf, sort.by="p")
V.144R.top= topTable(efit2, coef=3, adjust.method="BH", number=Inf, sort.by="p")
H3K27me3_24T <- volcanosig(V.24T.top, 0.05)+ ggtitle("DOX 24T")
H3K27me3_24R <- volcanosig(V.24R.top, 0.05)+ ggtitle("DOX 24R")+ylab("")
H3K27me3_144R <- volcanosig(V.144R.top, 0.05)+ ggtitle("DOX 144R")+ylab("")
plot_grid(H3K27me3_24T, H3K27me3_24R, H3K27me3_144R, rel_widths =c(1,1,1))H3K36me3
y <- voom(dge_H3K36me3, mm_H3K36me3, plot = FALSE)
corfit <- duplicateCorrelation(y, mm_H3K36me3, block = H3K36me3_annomat$ind)
v <- voom(dge_H3K36me3, mm_H3K36me3, block = H3K36me3_annomat$ind, correlation = corfit$consensus.correlation)
fit <- lmFit(v, mm_H3K36me3, block = H3K36me3_annomat$ind, correlation = corfit$consensus.correlation)
cm <- makeContrasts(
DOX_24T.VEH_24T = DOX_24T-VEH_24T,
DOX_24R.VEH_24R = DOX_24R-VEH_24R,
DOX_144R.VEH_144R = DOX_144R-VEH_144R,
levels = mm_H3K36me3)
fit2<- contrasts.fit(fit, contrasts=cm)
efit2 <- eBayes(fit2)
results = decideTests(efit2)
summary(results) DOX_24T.VEH_24T DOX_24R.VEH_24R DOX_144R.VEH_144R
Down 1541 209 2
NotSig 184086 186161 186722
Up 1097 354 0plotSA(efit2, main="Mean-Variance trend for final model for H3K36me3")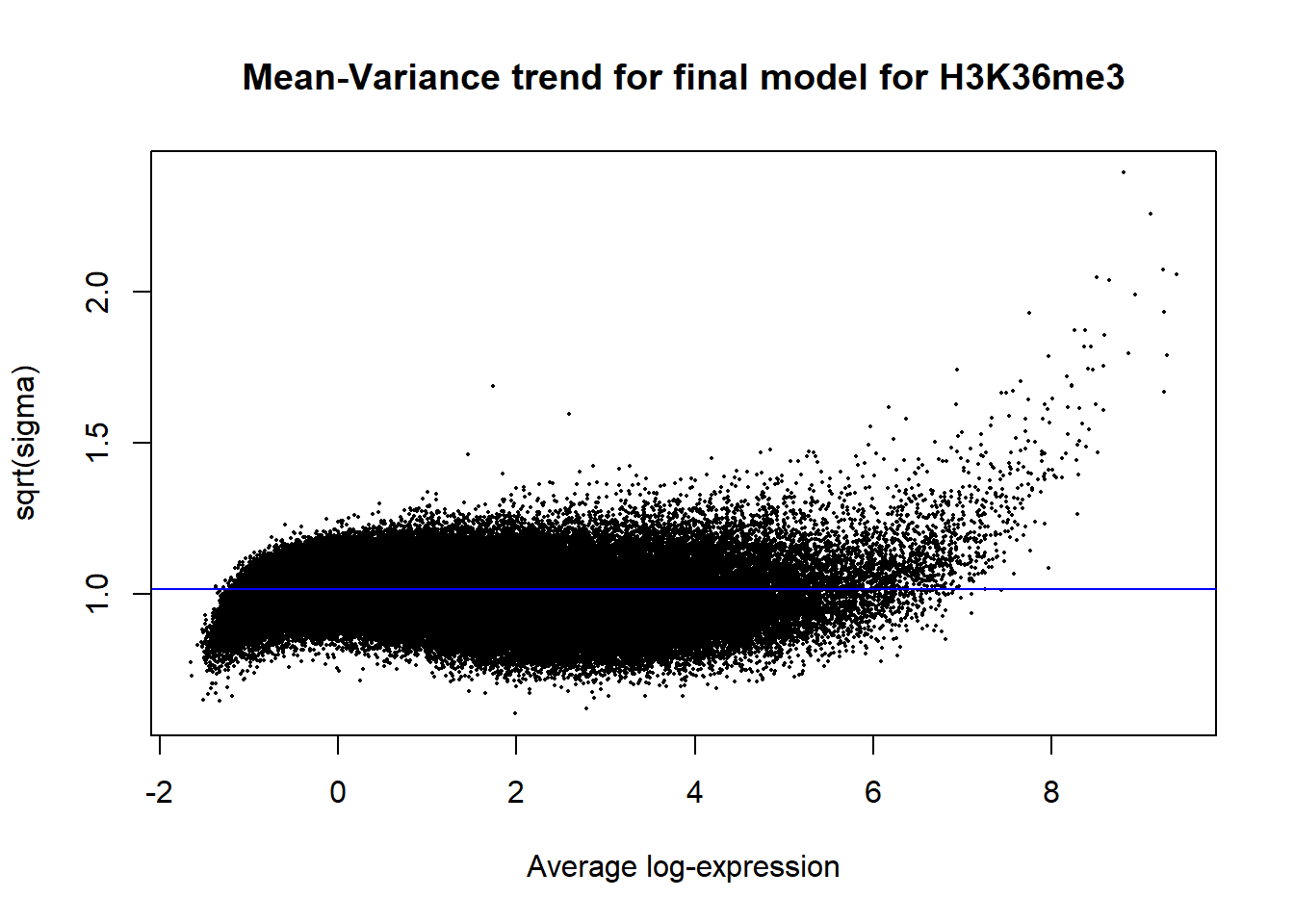
| Version | Author | Date |
|---|---|---|
| ac6eb8d | reneeisnowhere | 2025-08-21 |
V.24T.top= topTable(efit2, coef=1, adjust.method="BH", number=Inf, sort.by="p")
V.24R.top= topTable(efit2, coef=2, adjust.method="BH", number=Inf, sort.by="p")
V.144R.top= topTable(efit2, coef=3, adjust.method="BH", number=Inf, sort.by="p")
H3K36me3_24T <- volcanosig(V.24T.top, 0.05)+ ggtitle("DOX 24T")
H3K36me3_24R <- volcanosig(V.24R.top, 0.05)+ ggtitle("DOX 24R")+ylab("")
H3K36me3_144R <- volcanosig(V.144R.top, 0.05)+ ggtitle("DOX 144R")+ylab("")
plot_grid(H3K36me3_24T, H3K36me3_24R, H3K36me3_144R, rel_widths =c(1,1,1))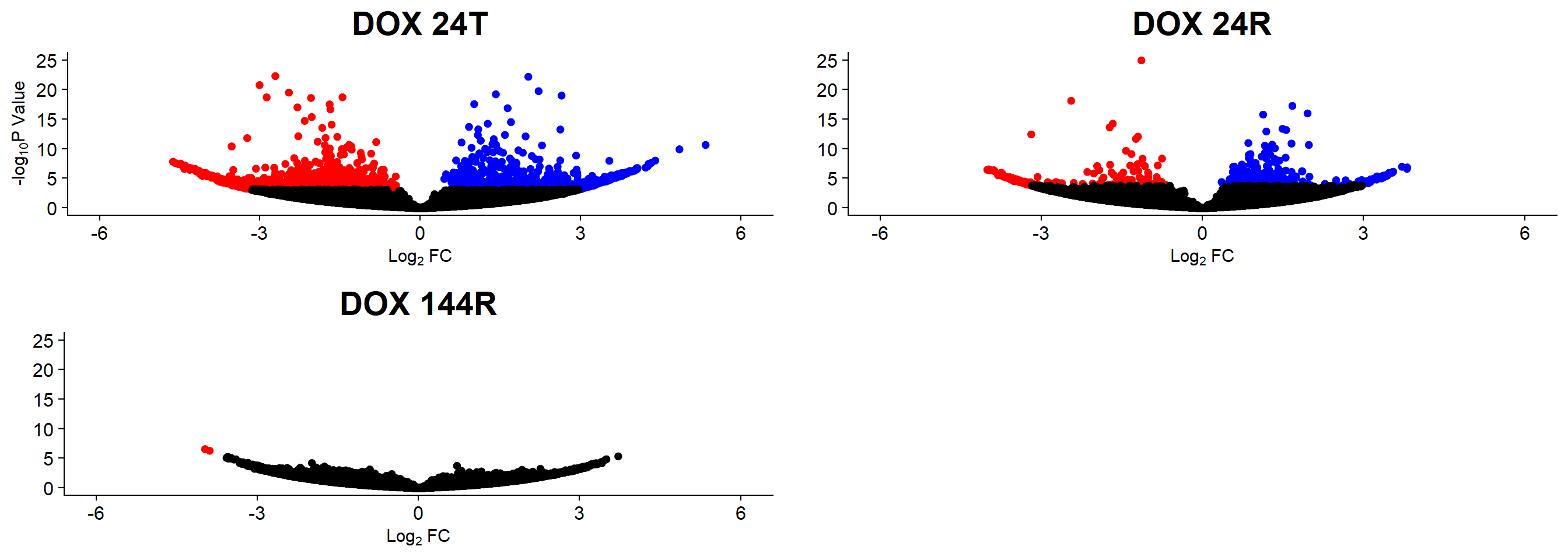
| Version | Author | Date |
|---|---|---|
| ac6eb8d | reneeisnowhere | 2025-08-21 |
H3K9me3
y <- voom(dge_H3K9me3, mm_H3K9me3, plot = FALSE)
corfit <- duplicateCorrelation(y, mm_H3K9me3, block = H3K9me3_annomat$ind)
v <- voom(dge_H3K9me3, mm_H3K9me3, block = H3K9me3_annomat$ind, correlation = corfit$consensus.correlation)
fit <- lmFit(v, mm_H3K9me3, block = H3K9me3_annomat$ind, correlation = corfit$consensus.correlation)
cm <- makeContrasts(
DOX_24T.VEH_24T = DOX_24T-VEH_24T,
DOX_24R.VEH_24R = DOX_24R-VEH_24R,
DOX_144R.VEH_144R = DOX_144R-VEH_144R,
levels = mm_H3K9me3)
fit2<- contrasts.fit(fit, contrasts=cm)
efit2 <- eBayes(fit2)
results = decideTests(efit2)
summary(results) DOX_24T.VEH_24T DOX_24R.VEH_24R DOX_144R.VEH_144R
Down 2530 10 0
NotSig 198298 218099 218647
Up 17819 538 0plotSA(efit2, main="Mean-Variance trend for final model for H3K9me3")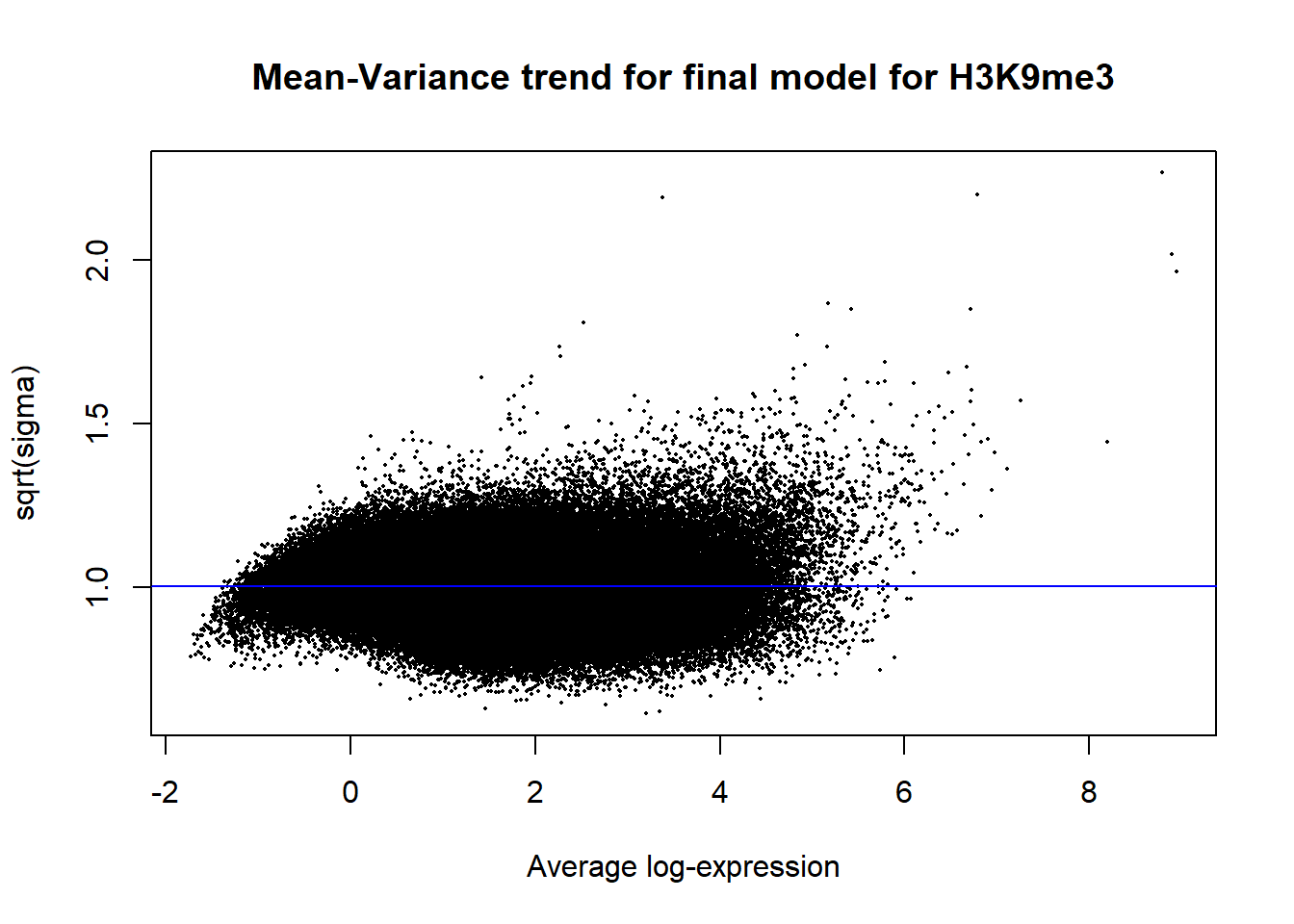
| Version | Author | Date |
|---|---|---|
| ac6eb8d | reneeisnowhere | 2025-08-21 |
V.24T.top= topTable(efit2, coef=1, adjust.method="BH", number=Inf, sort.by="p")
V.24R.top= topTable(efit2, coef=2, adjust.method="BH", number=Inf, sort.by="p")
V.144R.top= topTable(efit2, coef=3, adjust.method="BH", number=Inf, sort.by="p")
H3K9me3_24T <- volcanosig(V.24T.top, 0.05)+ ggtitle("DOX 24T")
H3K9me3_24R <- volcanosig(V.24R.top, 0.05)+ ggtitle("DOX 24R")+ylab("")
H3K9me3_144R <- volcanosig(V.144R.top, 0.05)+ ggtitle("DOX 144R")+ylab("")
plot_grid(H3K9me3_24T, H3K9me3_24R, H3K9me3_144R, rel_widths =c(1,1,1))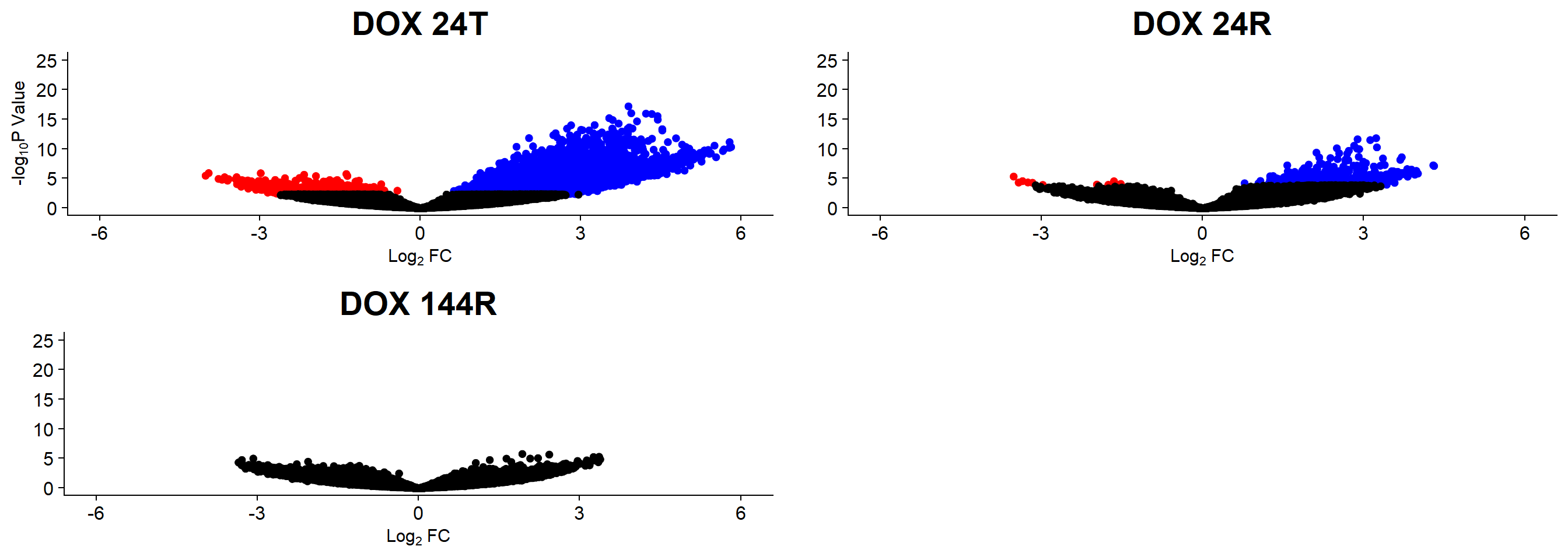
| Version | Author | Date |
|---|---|---|
| ac6eb8d | reneeisnowhere | 2025-08-21 |
Venn Diagrams
Venn Set Up
# genes_H3K27ac_24T <- H3K27ac_24T$data$genes[(H3K27ac_24T$data$adj.P.Val < 0.05)]
# genes_H3K27ac_24R <- H3K27ac_24R$data$genes[(H3K27ac_24R$data$adj.P.Val < 0.05)]
# genes_H3K27ac_144R <- H3K27ac_144R$data$genes[(H3K27ac_144R$data$adj.P.Val < 0.05)]
# genes_H3K27me3_24T <- H3K27me3_24T$data$genes[(H3K27me3_24T$data$adj.P.Val < 0.05)]
# genes_H3K27me3_24R <- H3K27me3_24R$data$genes[(H3K27me3_24R$data$adj.P.Val < 0.05)]
# genes_H3K27me3_144R <- H3K27me3_144R$data$genes[(H3K27me3_144R$data$adj.P.Val < 0.05)]
genes_H3K36me3_24T <- H3K36me3_24T$data$genes[(H3K36me3_24T$data$adj.P.Val < 0.05)]
genes_H3K36me3_24R <- H3K36me3_24R$data$genes[(H3K36me3_24R$data$adj.P.Val < 0.05)]
genes_H3K36me3_144R <- H3K36me3_144R$data$genes[(H3K36me3_144R$data$adj.P.Val < 0.05)]
genes_H3K9me3_24T <- H3K9me3_24T$data$genes[(H3K9me3_24T$data$adj.P.Val < 0.05)]
genes_H3K9me3_24R <- H3K9me3_24R$data$genes[(H3K9me3_24R$data$adj.P.Val < 0.05)]
genes_H3K9me3_144R <- H3K9me3_144R$data$genes[(H3K9me3_144R$data$adj.P.Val < 0.05)]H3K27ac Venn Diagrams
ggVennDiagram(list("24T regions"=genes_H3K27ac_24T,"24R regions"=genes_H3K27ac_24R, "144R regions"=genes_H3K27ac_144R))H3K27me3 Venn Diagrams
ggVennDiagram(list("24T regions"=genes_H3K27me3_24T,"24R regions"=genes_H3K27me3_24R, "144R regions"=genes_H3K27me3_144R))H3K36me3 Venn Diagrams
ggVennDiagram(list("24T regions"=genes_H3K36me3_24T,"24R regions"=genes_H3K36me3_24R, "144R regions"=genes_H3K36me3_144R))+
ggtitle("H3K36me3")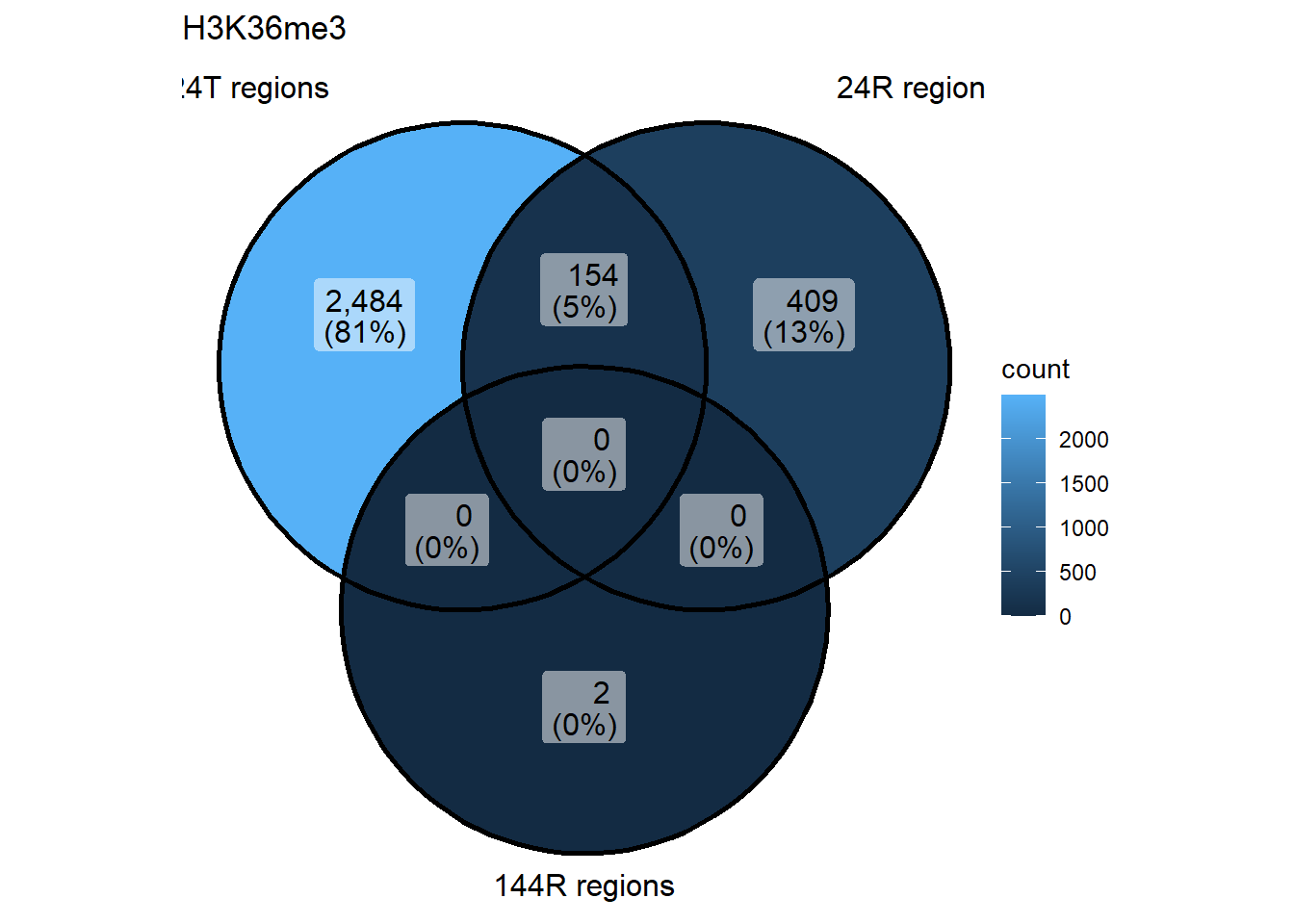
H3K9me3 Venn Diagrams
ggVennDiagram(list("24T regions"=genes_H3K9me3_24T,"24R regions"=genes_H3K9me3_24R, "144R regions"=genes_H3K9me3_144R))+ ggtitle("H3K9me3")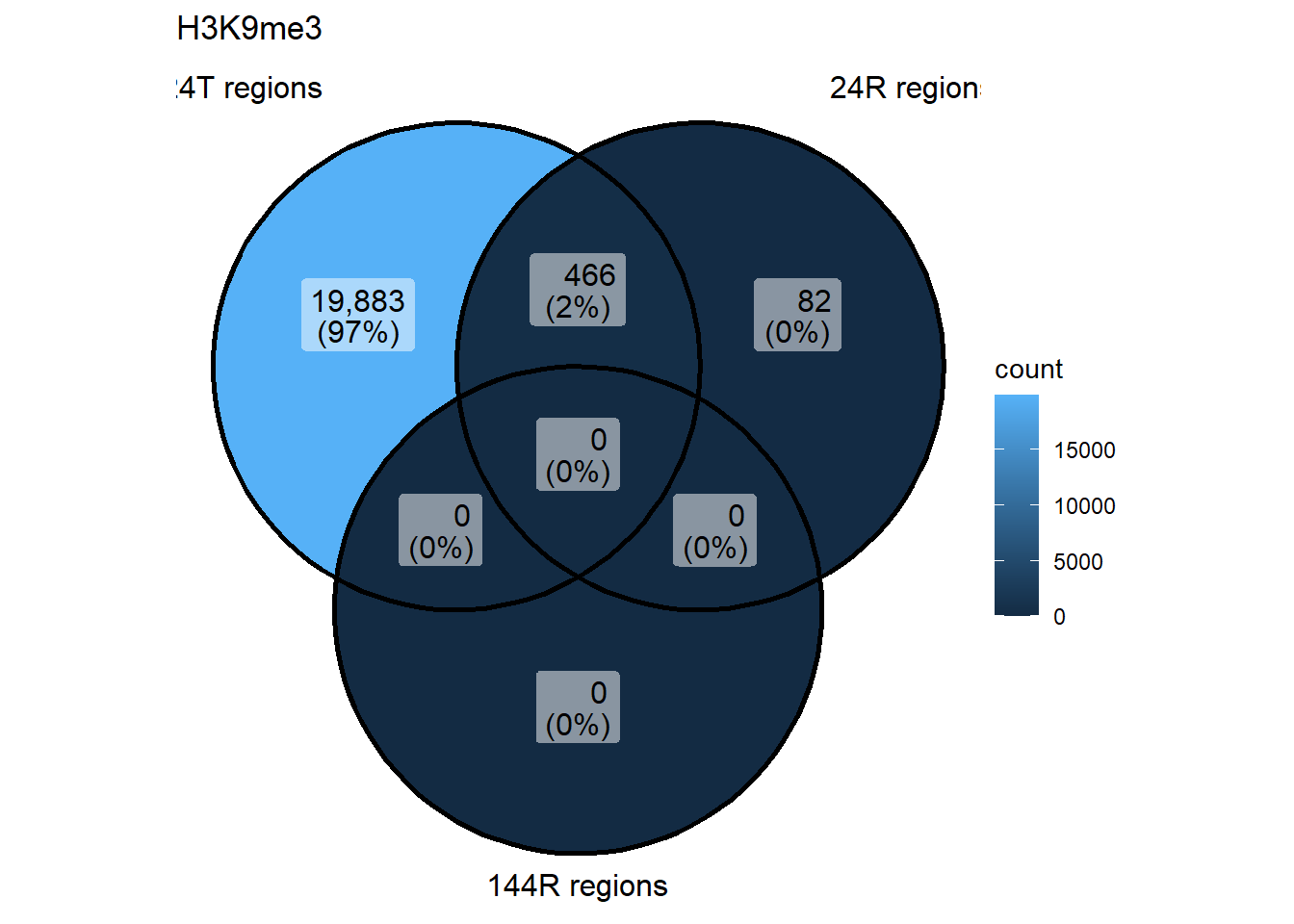
# H3K27ac_toplist <- list("H3K27ac_24T"=H3K27ac_24T$data,"H3K27ac_24R"= H3K27ac_24R$data, "H3K27ac_144R"= H3K27ac_144R$data)
# saveRDS(H3K27ac_toplist, "data/DER_data/H3K27ac_toplist_nooutlier.RDS")
# H3K27me3_toplist <- list("H3K27me3_24T"=H3K27me3_24T$data,"H3K27me3_24R"= H3K27me3_24R$data, "H3K27me3_144R"= H3K27me3_144R$data)
# saveRDS(H3K27me3_toplist,"data/DER_data/H3K27me3_toplist_nooutlier.RDS")
H3K36me3_toplist <- list("H3K36me3_24T"=H3K36me3_24T$data,"H3K36me3_24R"= H3K36me3_24R$data, "H3K36me3_144R"= H3K36me3_144R$data)
saveRDS(H3K36me3_toplist,"data/DER_data/H3K36me3_toplist_nooutlier.RDS")
H3K9me3_toplist <- list("H3K9me3_24T"=H3K9me3_24T$data,"H3K9me3_24R"= H3K9me3_24R$data, "H3K9me3_144R"= H3K9me3_144R$data)
saveRDS(H3K9me3_toplist, "data/DER_data/H3K9me3_toplist_nooutlier.RDS")
sessionInfo()R version 4.4.2 (2024-10-31 ucrt)
Platform: x86_64-w64-mingw32/x64
Running under: Windows 11 x64 (build 26100)
Matrix products: default
locale:
[1] LC_COLLATE=English_United States.utf8
[2] LC_CTYPE=English_United States.utf8
[3] LC_MONETARY=English_United States.utf8
[4] LC_NUMERIC=C
[5] LC_TIME=English_United States.utf8
time zone: America/Chicago
tzcode source: internal
attached base packages:
[1] stats4 grid stats graphics grDevices utils datasets
[8] methods base
other attached packages:
[1] ggVennDiagram_1.5.4 smplot2_0.2.5
[3] cowplot_1.2.0 ggrastr_1.0.2
[5] Rsubread_2.20.0 gcplyr_1.12.0
[7] ggpmisc_0.6.2 ggpp_0.5.9
[9] corrplot_0.95 ggpubr_0.6.1
[11] DESeq2_1.46.0 SummarizedExperiment_1.36.0
[13] Biobase_2.66.0 MatrixGenerics_1.18.1
[15] matrixStats_1.5.0 chromVAR_1.28.0
[17] GenomicRanges_1.58.0 GenomeInfoDb_1.42.3
[19] IRanges_2.40.1 S4Vectors_0.44.0
[21] BiocGenerics_0.52.0 genomation_1.38.0
[23] kableExtra_1.4.0 DT_0.33
[25] viridis_0.6.5 viridisLite_0.4.2
[27] data.table_1.17.8 ComplexHeatmap_2.22.0
[29] edgeR_4.4.2 limma_3.62.2
[31] lubridate_1.9.4 forcats_1.0.0
[33] stringr_1.5.1 dplyr_1.1.4
[35] purrr_1.1.0 readr_2.1.5
[37] tidyr_1.3.1 tibble_3.3.0
[39] ggplot2_3.5.2 tidyverse_2.0.0
[41] workflowr_1.7.1
loaded via a namespace (and not attached):
[1] fs_1.6.6 bitops_1.0-9
[3] DirichletMultinomial_1.48.0 TFBSTools_1.44.0
[5] httr_1.4.7 RColorBrewer_1.1-3
[7] doParallel_1.0.17 tools_4.4.2
[9] backports_1.5.0 R6_2.6.1
[11] lazyeval_0.2.2 GetoptLong_1.0.5
[13] withr_3.0.2 gridExtra_2.3
[15] quantreg_6.1 cli_3.6.5
[17] textshaping_1.0.1 Cairo_1.6-5
[19] labeling_0.4.3 sass_0.4.10
[21] Rsamtools_2.22.0 systemfonts_1.2.3
[23] foreign_0.8-90 svglite_2.2.1
[25] R.utils_2.13.0 dichromat_2.0-0.1
[27] plotrix_3.8-4 BSgenome_1.74.0
[29] pwr_1.3-0 rstudioapi_0.17.1
[31] impute_1.80.0 RSQLite_2.4.3
[33] generics_0.1.4 shape_1.4.6.1
[35] BiocIO_1.16.0 vroom_1.6.5
[37] gtools_3.9.5 car_3.1-3
[39] GO.db_3.20.0 Matrix_1.7-3
[41] ggbeeswarm_0.7.2 abind_1.4-8
[43] R.methodsS3_1.8.2 lifecycle_1.0.4
[45] whisker_0.4.1 yaml_2.3.10
[47] carData_3.0-5 SparseArray_1.6.2
[49] blob_1.2.4 promises_1.3.3
[51] crayon_1.5.3 pwalign_1.2.0
[53] miniUI_0.1.2 lattice_0.22-7
[55] annotate_1.84.0 KEGGREST_1.46.0
[57] magick_2.8.7 pillar_1.11.0
[59] knitr_1.50 rjson_0.2.23
[61] codetools_0.2-20 glue_1.8.0
[63] getPass_0.2-4 vctrs_0.6.5
[65] png_0.1-8 gtable_0.3.6
[67] poweRlaw_1.0.0 cachem_1.1.0
[69] xfun_0.52 S4Arrays_1.6.0
[71] mime_0.13 survival_3.8-3
[73] iterators_1.0.14 statmod_1.5.0
[75] bit64_4.6.0-1 rprojroot_2.1.0
[77] bslib_0.9.0 vipor_0.4.7
[79] KernSmooth_2.23-26 rpart_4.1.24
[81] colorspace_2.1-1 seqLogo_1.72.0
[83] DBI_1.2.3 Hmisc_5.2-3
[85] seqPattern_1.38.0 nnet_7.3-20
[87] tidyselect_1.2.1 processx_3.8.6
[89] bit_4.6.0 compiler_4.4.2
[91] curl_7.0.0 git2r_0.36.2
[93] htmlTable_2.4.3 SparseM_1.84-2
[95] xml2_1.4.0 DelayedArray_0.32.0
[97] plotly_4.11.0 rtracklayer_1.66.0
[99] checkmate_2.3.3 scales_1.4.0
[101] caTools_1.18.3 callr_3.7.6
[103] digest_0.6.37 rmarkdown_2.29
[105] XVector_0.46.0 htmltools_0.5.8.1
[107] pkgconfig_2.0.3 base64enc_0.1-3
[109] fastmap_1.2.0 rlang_1.1.6
[111] GlobalOptions_0.1.2 htmlwidgets_1.6.4
[113] UCSC.utils_1.2.0 shiny_1.11.1
[115] farver_2.1.2 jquerylib_0.1.4
[117] zoo_1.8-14 jsonlite_2.0.0
[119] BiocParallel_1.40.2 R.oo_1.27.1
[121] RCurl_1.98-1.17 magrittr_2.0.3
[123] polynom_1.4-1 Formula_1.2-5
[125] GenomeInfoDbData_1.2.13 patchwork_1.3.1
[127] Rcpp_1.1.0 stringi_1.8.7
[129] zlibbioc_1.52.0 MASS_7.3-65
[131] plyr_1.8.9 ggrepel_0.9.6
[133] parallel_4.4.2 CNEr_1.42.0
[135] Biostrings_2.74.1 splines_4.4.2
[137] hms_1.1.3 circlize_0.4.16
[139] locfit_1.5-9.12 ps_1.9.1
[141] ggsignif_0.6.4 reshape2_1.4.4
[143] TFMPvalue_0.0.9 XML_3.99-0.18
[145] evaluate_1.0.4 tzdb_0.5.0
[147] foreach_1.5.2 httpuv_1.6.16
[149] MatrixModels_0.5-4 clue_0.3-66
[151] gridBase_0.4-7 broom_1.0.9
[153] xtable_1.8-4 restfulr_0.0.16
[155] rstatix_0.7.2 later_1.4.2
[157] memoise_2.0.1 beeswarm_0.4.0
[159] AnnotationDbi_1.68.0 GenomicAlignments_1.42.0
[161] cluster_2.1.8.1 timechange_0.3.0